
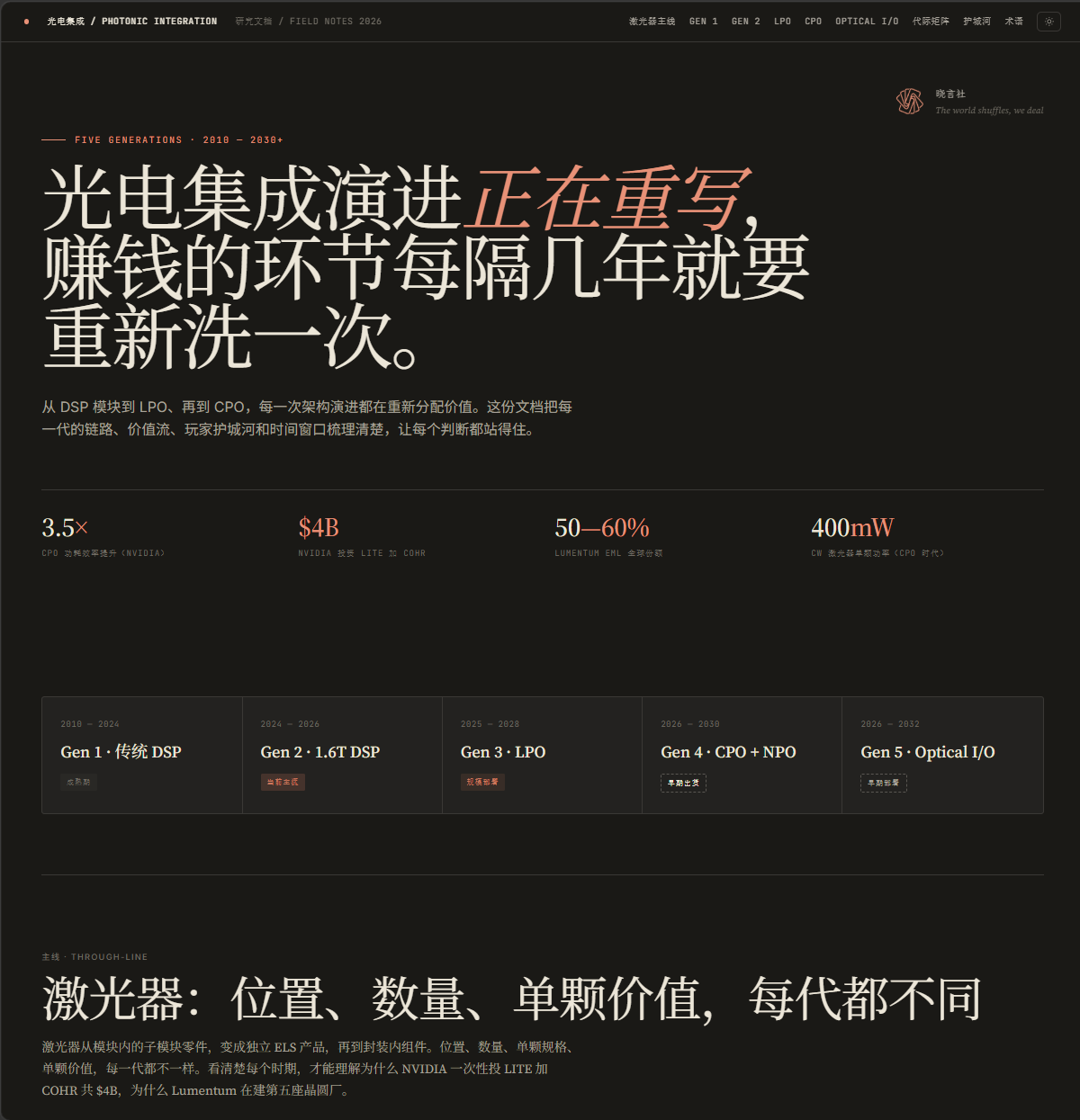
2026 - 2035 让我们重写光的价值链
多数人把 AI 光互连看成一个看对一次就只能赚到一次的主题。这是误读。从2026到2035,从传统 DSP 模块到光进 GPU 封装,有的是机会。

0 前言
2026 年初,NVIDIA 一次性掏 $4B,押给两家做激光器的公司,Lumentum 跟 Coherent。几乎同一时间,Marvell 花 $3.25B 买下一家做芯片间光互连的初创 Celestial AI。NVIDIA 又投钱给法国一家做多波长激光器的小公司 Scintil。
这些钱,一笔一笔砸在了光电集成上。本文深度全面全程讲解数据中心加速计算光电集成演进图谱。可以帮你学习这一个热门产业,发掘宏观下的机会。本文主要面向市场参与者,部分论断与细节可能与具体工程仍有出入。主要展示产业逻辑,具体公司情况需要自行尽调。并且市场情绪可以很轻松超过基本面,尤其是原先无人在意的小公司。
我也是因为有这个图谱在脑海中,提前在大家疯狂fomo lite等大厂时,低位买入了nok,himx,aehr,axti等。这个思维习惯,也有助于帮助大家寻找挖掘不拥挤的机会。今天也把这个图谱整理成正式的展示网页和文稿,分享给大家。
网页信息量很大,文章中无法完全照顾到所有的专业技术信息,具体的技术名词,对应的功能在网页中都有事无巨细的解释与讲解。Link放在文章第二部分开头。
1. 背景
1.1 长距离 GPU 互联只能用光,链路上有六个核心零件
一个大型 AI 训练集群里有几万颗 GPU,分布在几百个机柜里。训练大模型时这些 GPU 要持续互相同步,每颗卡算出的参数、中间结果和协调任务都要传给其他卡。同步速度要接近瞬时,慢一点 GPU 就会空等数据,几亿美元的硬件随之闲置。
GPU 之间的通信走线。大体上短距离(同机柜内)用铜,距离一长就要换成光。
这是物理条件决定的。铜线在每秒 800Gbps 以上信号衰减很快,只能传几米。要更快更远,必须把电信号转成光,通过玻璃纤维传输。
铜到顶有两个原因。一个是信号衰减。铜线有跟频率相关的插入损耗,速率爬到每秒 800Gbps 以上以后,损耗预算在一两米内就耗尽,信号还原不出来。这是最硬的物理限制,给再大功率也过不去。另一个是驱动功耗和散热。速率越高、距离越远,需要的均衡、retimer 和驱动越强,这部分功耗在交换机端转成热;高速铜线又粗又重,密集机柜里还会挡住风道。信号衰减决定了铜传不远,驱动功耗和散热决定了即使勉强能传,代价也越来越不划算。要更快更远,就必须把电信号转成光,通过玻璃纤维传输。其中驱动功耗这一条,第 2 节会作为推动换代的力量之一展开。
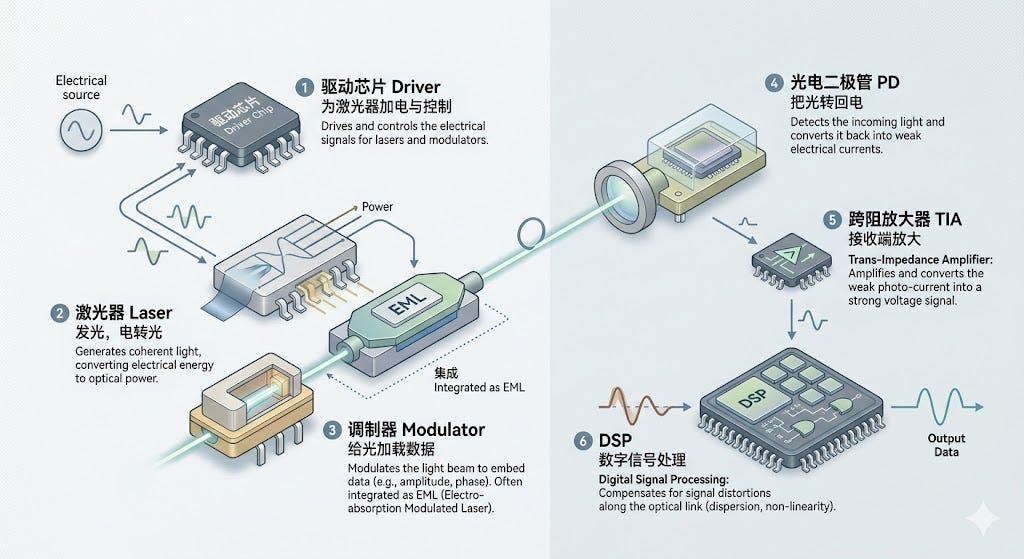
AI 数据中心里有一类核心组件叫光电集成链路,覆盖电变光、光走纤、光变电的全过程。其中比较核心的是:
• 激光器:发光,把电变光
• 调制器:给光加载数据,常和激光器集成,合称 EML
• 驱动芯片 Driver:给激光器加电
• 跨阻放大器 TIA:接收端把微弱光信号放大成电
• DSP:数字信号处理器,补偿光路上的失真
• 光电二极管 PD:把光转回电
完整可交互版本见研究网页。
这些零件组成一颗光模块,插在交换机或 GPU 板上,负责一段距离的传输。一台 AI 训练交换机要插几百颗光模块。2025 年光模块全球出货量约 6300 万只。
光电集成在不同距离层级上做的事不同:
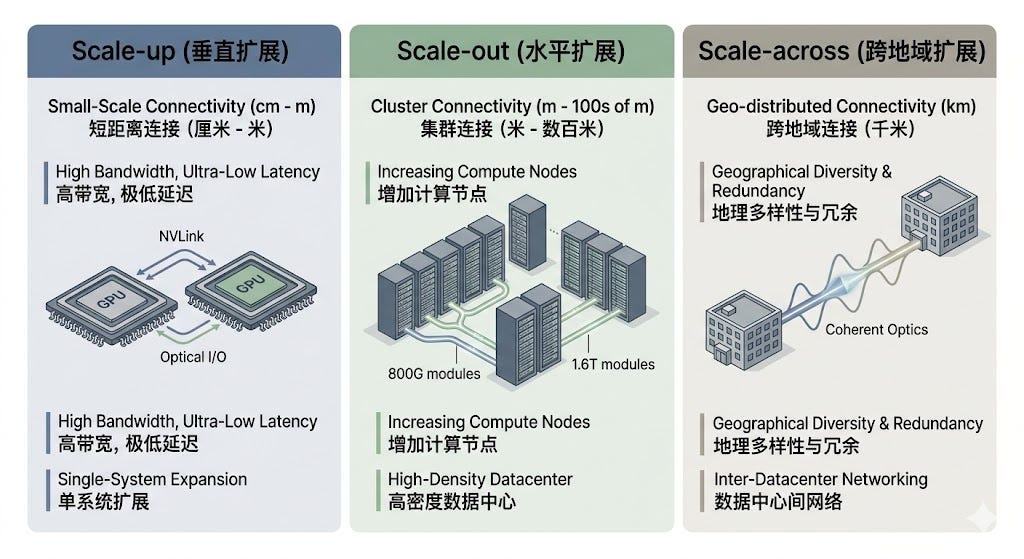
• scale-out(机柜之间、楼之间,几米到几百米):800G、1.6T 光模块是主战场。本文 Gen 1 到 Gen 4 讲的都是 scale-out。
• scale-up(GPU 之间、芯片之间,几厘米到几米):目前仍是铜(NVLink、PCIe)。带宽到 800Gbps 以上铜传不到,光开始替代铜。Gen 5 Optical I/O 就是把光做进 scale-up。
• scale-across(跨园区、跨城,几公里以上):用相干光(ZR / ZR+ 模块),本文不展开。
NVIDIA 那 $4B 投的是 scale-out 和 scale-up 两层链路上的零件,具体是 CPO 时代的 CW 激光器(scale-out 用)和下一代 Optical I/O 的封装内激光器(scale-up 用)。
1.2 速率、功耗、铜的极限,三股力量逼链路换代
光电集成不是新技术,数据中心一直在用光。最近几年它的换代频率明显加快。推动换代的有三股力量。
速率往上走:一根光纤里能承载的数据量从 100Gbps 爬升到 800G、1.6T、3.2T。每翻一倍,光路里所有零件的工艺难度都跳一级,部分零件直接不能用。
功耗墙逼近:AI 集群规模上来后,数据中心总耗电量大幅上升。光电集成占数据中心总功耗的 5% 到 8%,同时热量问题不优化就会成为下一代规模化的瓶颈。每一代演进的核心动作经常是砍掉某个耗电的零件。
铜的物理极限:GPU 内部、芯片与芯片之间目前还是铜。带宽往 800Gbps 以上爬,铜传几米就到顶。方向是把光做进 GPU 封装内部、替代铜。一旦做到,光电集成的市场规模会从每台交换机几百颗,跳到每颗 GPU 都要。
过去 5 年的光电集成演进,本质是速率上升、功耗墙、铜的物理极限合起来重写整条链路。
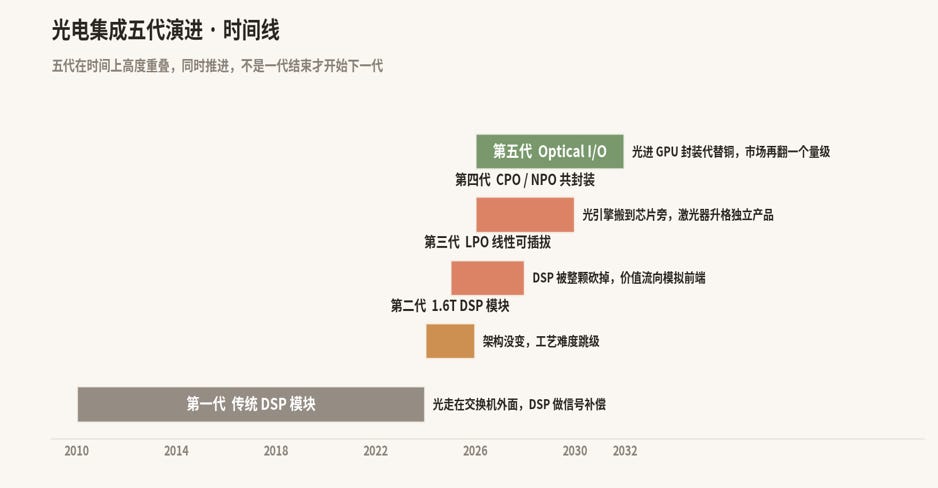
1.3 五代链路同时放量,从 DSP 模块走到光进 GPU 封装
五代同时 ramp。Gen 2 当前主流,Gen 3 进入规模部署,Gen 4 早期出货,Gen 5 在卖样品。Meta 量产 LPO,NVIDIA 出货 CPO,Marvell 以 $3.25B 收购 Celestial AI 进入 Optical I/O。每一代演进,光路零件的位置、数量、单颗价值都在变,这也是我们的机会所在。
1.4 激光器从模块零件变成独立产品
激光器一直在链路里,但每代它的角色也有所不同。
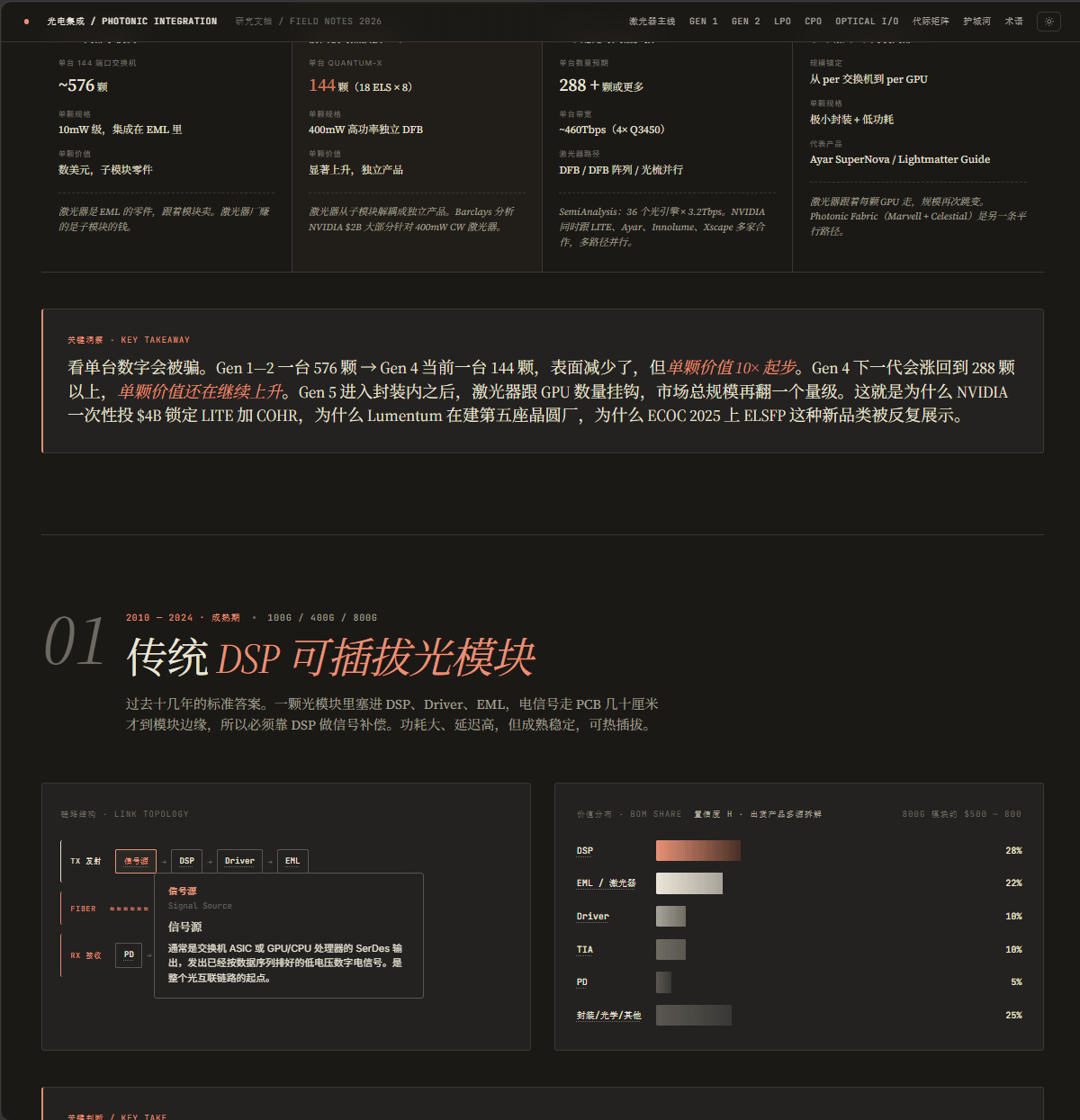
单看每台数量会产生误读。Gen 1 到 2 一台 576 颗,Gen 4 当前一台 144 颗,表面减少约 4 倍,而单颗价值从 10 倍起步。Gen 4 下一代会涨回 288 颗以上,单颗价值继续上升。Gen 5 进入封装内之后,激光器数量和 GPU 数量挂钩,市场总规模再翻一个量级。
数量减少约 4 倍,单颗价值上升 10 倍以上,合并起来仍是净扩张。
这就是 NVIDIA 一次性投 $4B 锁定 Lumentum 加 Coherent 的原因。Barclays 拆解过这 $4B 的去向,大部分是针对 400mW CW 激光器的多年期采购承诺。激光器在链路里的数量在减少,激光器生意却在变大,它从模块里的子零件变成了前面板的独立产品。
https://opticalevolution.theshuffle.workers.dev/

2. 代际演进
2.1 Gen 1:DSP 主导,过去十几年的标准结构
时间:2010 到 2024。速率 100G / 400G / 800G。
要解决的问题:数据中心交换机之间几十米到几百米的距离,铜线传不到,要把电信号扛过去就必须做电光转换。
标准结构:一颗光模块里塞进 DSP、Driver、EML,做成可热插拔的标准件。电信号在 PCB 上走几十厘米才到模块边缘,必须靠 DSP 做信号补偿才能把失真扳回来。功耗大、延迟高,但成熟稳定。
链路:信号源 → DSP → Driver → EML → 光纤 → PD → TIA → DSP → SerDes。
价值分布(800G 模块约 $500 到 800):DSP 28%,EML / 激光器 22%,Driver 10%,TIA 10%,PD 5%,封装 / 光学 / 其他 25%。
关键玩家:Broadcom 的 Portofino 7nm DSP 加上 Marvell 的 Inphi DSP 垄断高速 DSP,合计约 65% 份额(第三家 MaxLinear 起量后双寡头格局开始松动)。Lumentum 是 EML 全球第一(50% 到 60%),Coherent 第二(约 25%)。MACOM 在高速 TIA / Driver 上份额最高。
设备 / 量测:工艺重心在 InP 激光器制造,封装是成熟可插拔模块,没有特殊瓶颈。InP 外延镀膜设备(Veeco、AIXTRON)的价值从这一代开始释放,会贯穿后面所有用 InP 激光器的世代。封装量测的价值要到 Gen 4 CPO 才真正放大。
关键判断:DSP 是这个时代单 BoM 占比最高的环节。Broadcom 和 Marvell 是过去十年估值最高的两家光电集成玩家,而MXL就是老三。这个结构稳定了十几年,到 1.6T 时代才开始松动。
2.2 Gen 2:1.6T 工艺门槛卡在 Lumentum 一家
时间:2024 到 2026。速率 1.6Tbps,200G/lane × 8 通道。
上一代的瓶颈:800G 不够用。GPU 集群规模上去后,交换机背板带宽要翻倍,需要 1.6T 模块。
这一代的解法:架构没变,还是 DSP + Driver + EML + TIA + DSP 那一套,但每个零件的工艺难度都跳一级。DSP 升到 7nm,EML 升到 200G/lane,Driver / TIA 跟上线性度。
代价:单模块 BoM 成本翻倍($1,000 到 1,500)。200G EML 几乎只有 Lumentum 能量产,工艺门槛把行业卡在一家手里。
价值分布(1.6T 模块约 $1,000 到 1,500):DSP 30%(+$150),200G EML 28%(+6%),Driver 11%,TIA 11%,PD 5%,其他 15%。
门槛跳变:200G EML 几乎是 Lumentum 独家。Coherent 在追赶,但 6 英寸 InP 产线要 2026 年底才贡献产能。独家工艺、长协锁定、产能不足 30%,合起来是 LITE 2026 YTD 涨 180% 的核心原因。
关键玩家:Lumentum,200G EML 独家,YTD +180%。Broadcom,7nm DSP 约 40%,Portofino 是 1.6T 模块事实标准。Marvell,7nm DSP 约 25%,NVIDIA 战投 $2B 加 NVLink Fusion 整合。MaxLinear,DSP 第三家,Keystone 800G 已在多家云厂商量产,2026 Q1 基础设施业务同比 +136%,1.6T DSP 2026 H2 量产,双寡头格局首次被实质打破。MACOM,NVIDIA 自产 1.6T 模块 Driver / TIA 唯一供应商,FY Q2 营收 $289M,YoY +22.5%,新接订单 / 出货比 1.5:1 创历史新高。Coherent,EML 第二,6 英寸 InP 量产是关键追赶。Innolight(中际旭创),中国最大光模块厂,NVIDIA 主要外购方,但 NVIDIA 自产率从 15% 到 20% 提到 50%+ 是直接挤压。第二供应源方向:200G EML 卡在一两家手里是这一代的结构性风险,Almae(法国,光迅持股)提供独立 EML 设计平台,是 Lumentum / Coherent 之外的第三家选项。
设备 / 量测:200G EML 卡在 Lumentum 一家,工艺门槛在 InP 外延和镀膜上。这是 InP 外延设备(Veeco、AIXTRON)价值释放最强的一段,800G / 1.6T 收发器厂是订单主力。封装仍是成熟模块,无新增量测瓶颈。
关键判断:Gen 2 的价值变化都发生在原有链路结构里。架构层的真改动从 Gen 3 开始。
2.3 Gen 3:LPO 砍掉 DSP,价值移到模拟前端
时间:2025 到 2028。速率 800G / 1.6T,数据中心内部。
上一代的瓶颈:1.6T DSP 模块太耗电。DSP 占 BoM 的 30%,功耗占模块总功耗的 30% 到 40%。AI 集群规模再扩,光电集成功耗墙先撞上。
这一代的解法:把 DSP 整颗砍掉。原本 DSP 负责的信号补偿,改由交换机 ASIC 自带的高线性 SerDes 加上模块内的 Linear Driver 和 Linear TIA 一起承担。功耗降一半,延迟降一个数量级,模块成本下来。
代价:模拟器件的线性度要求大幅提升,单颗 TIA / Driver 的设计难度跳升 2 到 3 倍,单价跟着上去,能做的厂大幅减少。速率上限被卡在 1.6T,3.2T 上力不从心。
链路:信号源 →(去掉 DSP)→ Linear Driver↑↑ → EML → 光纤 → PD → Linear TIA↑↑ →(去掉 DSP)→ SerDes 直驱。
价值分布(1.6T LPO 模块约 $700 到 1,000):DSP 0%(−100%),EML 35%(+3%),Linear Driver 22%(+13%),Linear TIA 20%(+12%),PD 6%(+1%),其他 17%。DSP 原本那 28% 没了,价值流向 Linear Driver 和 Linear TIA,这是 MACOM 的核心业务。
关键玩家:MACOM,LPO 路线最大受益方,PURE DRIVE 系列明确定位为 DSP 替代方案。Coherent,垂直一体化让它能在自家 LPO 模块里集成 Driver / TIA,但独立芯片业务弱于 MACOM。Lumentum,路径中立,EML 在 LPO 路线下不变,仍是发射端核心。Broadcom / Marvell,DSP 业务在 LPO 模块里被消灭,有 SerDes 升级对冲。Meta,公开站队 LPO 的代表 hyperscaler。OIF 800G LPO 标准 2025 OFC 完成,多供应商可用。硅光集成方向:传统硅光要外接激光器,效率低、组装贵。POET(Optical Interposer 平台)和 OpenLight(把 III-V 直接做在硅光晶圆上)从这个切面切入,都已在 800G / 1.6T 拿到量产订单。
设备 / 量测:LPO 砍掉 DSP 后模块结构反而简化,没有新增的设备封装大瓶颈。InP 激光器还在用,外延镀膜设备延续需求但不是新看点。硅光晶圆检测量测开始出现,但要等 Gen 4 CPO 才集中放大。
关键判断:LPO 的核心动作是消灭 DSP,价值从 DSP 流向 Linear Driver / TIA。MACOM 是这一代的单点最大受益者。
2.4 LPO 和 CPO 平行竞争,时间窗高度重叠
把五代看成线性演进,容易误以为 LPO 是 CPO 的过渡。LPO(2025 到 2028)和 CPO(2026 到 2030)在时间上高度重叠,两条架构并行竞争。LPO 渗透足够快、成本下降足够陡,CPO 的窗口期就会被压缩。
1.6T 阶段 LPO 大概率主流。CPO 在 3.2T+ 之后才被强制需要,两条路并存到 2028 之后。站队也清楚:Meta 走 LPO(OIF MSA Co-Chair 是 Arista 的 Andreas Bechtolsheim),NVIDIA 走 CPO。
路径独立的两类组件,MACOM 的 Driver / TIA 和 Lumentum 的 CW 激光器,两条路都受益。EML 业务只在 1.6T 时代有窗口,3.2T 时代被 TFLN(铌酸锂薄膜)替代的风险升高。
2.5 Gen 4:光引擎搬进 ASIC 旁,激光器独立出来
时间:2026 到 2030。速率 3.2T,数据中心 scale-out。
上一代的瓶颈:LPO 速率封顶 1.6T。3.2T 速率上,SerDes 信号在 PCB 上跑几十厘米后失真严重,模拟前端撑不住。
这一代的解法:把整个光引擎封装到交换机 ASIC 旁边,电信号路径从几十厘米缩到几毫米,DSP 在物理上变得不必要。EML 被拆分,CW 激光器独立成可热插拔的 ELS 模块(单独卖),调制功能交给硅光调制器。激光器从零件变成独立产品就发生在这一步,也是 NVIDIA $4B 投的那个位置。
代价:故障维修难(光引擎坏要拆服务器或换板)。生态还在磨合(NVIDIA + TSMC + 三家 ELS 供应商)。整机成本上升。
NPO 是同代的折中:CPO 把光引擎封死在 ASIC 旁边,坏了维修要拆整块。变体 NPO 把光引擎放在 ASIC 旁边但可以拆下来单独换,电路径接近 CPO,维修保留可插拔。对 Meta、AWS 这种在意运维的客户,NPO 是 CPO 的现实折中。两者技术栈高度重合,玩家几乎一样,差别在维修便利和集成度之间取舍。
链路:ASIC + 光引擎 → 外置 CW → 硅光调制器 → 光纤 → Si PD → die-to-die TIA → ASIC SerDes。消失的环节:DSP retimer、独立 EML、模块连接器。
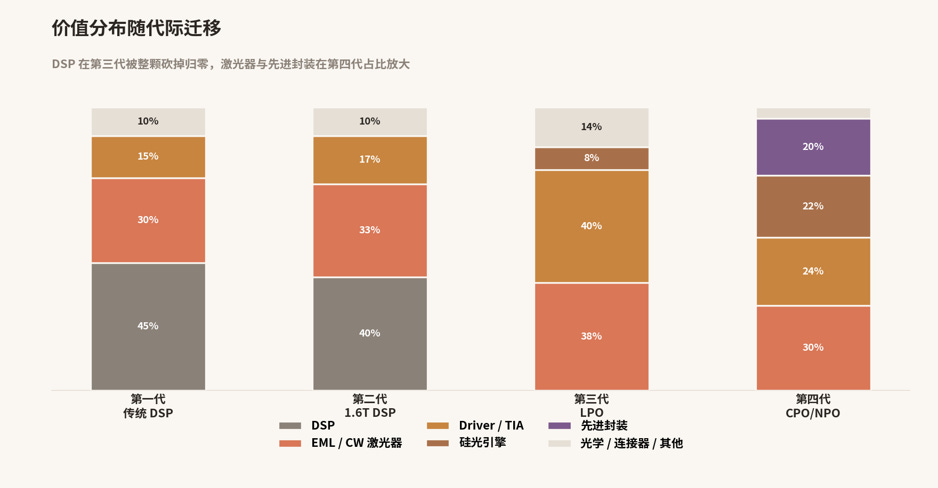
价值分布(Q3450 整机 ELS + 光引擎约 $35K 到 40K):DSP 0%(−100%),CW Laser(ELS)30%,硅光引擎 22%(新增),die-Driver 12%,die-TIA 12%,先进封装 20%(新增),光学 / 连接器 4%。一台交换机的激光器数量减少约 4 倍,单颗从 EML 内部隐性子模块变成 400mW 高功率独立产品。NVIDIA $4B 投资 Lumentum 加 Coherent,大部分针对 400mW CW 激光器。数量减少、单价上涨,合并仍是扩张。
工艺底座:CPO 是多个工艺迭代叠加的结果。TSMC 的 COUPE 用 hybrid bonding(DBI)把电芯片和硅光芯片键合在一起,是 CPO 的物理实现基础。3.2T 时代调制器材料从 InP 转向 TFLN(铌酸锂薄膜,带宽 >100GHz,CMOS 兼容),是下一个材料浪潮。国内光库科技(300620)是全球唯三量产 TFLN 之一。
关键玩家:CW Laser / ELS:Lumentum、Coherent、Sumitomo(NVIDIA 官方列出三家),Applied Optoelectronics(AAOI)2025 年宣布 400mW pump laser,Q1 2026 营收 $151M(YoY +51%),YTD +488%。CPO 平台:NVIDIA Quantum-X 主导,Broadcom Bailly 51.2T,Meta 评估中。先进封装:TSMC CoWoS + COUPE,SPIL 做 NVIDIA CPO multi-chip module 封装。die-to-die TIA / Driver:MACOM,FY Q1 2026 财报提到 CW 激光器早期量产认证。代工 / 光纤:Fabrinet,Corning 拿到 NVIDIA $500M 光连接合同,扩 10x 产能。
这一代的几条解法路线:光引擎封进 ASIC 旁边会同时撞上三个工程瓶颈,每个都有公司专门攻。调制器在 200G/lane 以上速率不够(Lightwave Logic 用电光聚合物),激光器数量爆炸(Quintessent 用量子点让一颗激光器出多波长),电芯片和硅光芯片怎么键合(Adeia 的 hybrid bonding IP,另有 Aeluma 用 MOCVD 直接把材料长在硅片上)。这些是 CPO 能否落地的关键支撑,每一条都是很细的技术分支。
设备 / 量测,价值集中放大:前三代封装是成熟模块,设备量测是配角。CPO 把光引擎封进 ASIC 之后,封装、光纤耦合、对准、晶圆级测试从次要变成决定良率的命门,因为 CPO 封装后光引擎坏了报废整颗 ASIC,封装前的检测和老化测试价值被大幅放大。这一代涉及四类环节:光纤耦合元器件(FOCI 的 FAU、Himax 的 WLO 组件、Largan / Sunny 跨界做棱镜、Teramount 免对准耦合),键合设备(BESI / ASMPT / EVG 的 hybrid bonding),装配对准(ficonTEC,强路径独立),检测测试(KLA / Onto / Camtek 检测,Advantest / Teradyne / Aehr 测试老化)。这层大多路径独立,不管哪条 CPO 路线赢都要用。
关键判断:CPO 把价值从模块层分散到两端,一端是独立卖的激光器,一端是先进封装。中间的 DSP 和独立 EML 是这一代的输家。
2.6 Gen 5:Optical I/O,光进 GPU 封装替代铜
时间:2026 到 2032。速率:芯片间 / GPU 间互联。
上一代的瓶颈:即使有 CPO,GPU 内部、GPU 与 GPU 之间的通信还是铜(NVLink 这类)。带宽往 800Gbps 以上爬,铜传几米就到极限。
这一代的解法:把光做到芯片或封装内部,直接替代铜。GPU 之间、CPU 和内存之间、芯片和封装之间,全部用光。
代价:还在 pre-revenue 阶段。Ayar Labs CEO 预测 2026 到 2028 市场开始成熟,2028 后大规模扩散。Marvell 2026 年初以 $3.25B 收购 Celestial AI 抢入场券,商业化时间表至少到 2028。
链路:Chip A → 硅光 PIC → WDM 多路复用 → 光波导 / 光纤 → WDM 解复用 → 硅光 PIC → Chip B。
价值分布(置信度 L,pre-revenue 早期估算,单链路价值未知):硅光 PIC 约 40%,WDM 约 25%,CW Laser 约 20%,先进封装约 15%。
关键玩家:Ayar Labs(未上市),2026 年 3 月 Series E 融资 $500M,估值 $3.75B,NVIDIA + AMD + MediaTek + Alchip 战投,TeraPHY 是首个 UCIe 兼容光互连 chiplet。Lightmatter(未上市),估值 $4.4B,累计融资 $850M,Passage 3D 共封装加 Envise 光计算两条线。Celestial AI,2026 年初被 Marvell 以 $3.25B 收购,Photonic Fabric 直接把光送到芯片任意位置。POET、Lightwave Logic,公开市场的高 beta,pre-revenue。Scintil Photonics,NVIDIA 2025 年 9 月战投,法国多波长激光器。NVIDIA,投了 Coherent、Lumentum、Ayar Labs、Scintil,全方位卡位。TSMC、GlobalFoundries,硅光代工。
设备 / 量测,价值转移:集成度比 CPO 更高,封装前测试和精密装配的重要性继续上升,Aehr / Teradyne / ficonTEC 进一步强化,这是设备量测层里确定性最高的环节。价值转移发生在链路测试这端:EXFO / Viavi / Keysight 过去靠可插拔模块的产线测试,光进 GPU 封装之后,这部分需求转移到上游晶圆级测试。同一笔测试价值从模块产线挪到晶圆厂,没有消失,只是换了环节收费。这是设备量测层内部随演进迁移的典型例子。
关键判断:Optical I/O 还在大规模商用前的小批量试用阶段。一旦成熟,整个数据中心的互联架构会被重写。铜的物理极限让光成为唯一选项。
3. 总体市场
3.1 五家 hyperscalers 路径不同,但组件层需求被总体放大
NVIDIA 的 CPO 路线不等于行业方向。Google、Meta、Amazon、Microsoft 各走自己的路。
五家走五路,含义分两面看。对组件层(CW 激光器、Driver / TIA、InP / TFLN 调制器)的需求,分母变大,不管哪条路赢都要用。对架构特定厂(只绑 NVIDIA Quantum-X 链路)的依赖,分子变小,因为 NVIDIA 只占 hyperscaler 部署的一部分。
未来 3 年是多路径并存。Lumentum、MACOM、TSMC 这种路径独立玩家受益大。
3.2 市场在扩张,1.6T 单价下行和 capex 回撤是两个风险
供给侧只是一半。需求侧是另一半:每代 TAM 量级、S 曲线拐点位置、AI capex 2026 到 2027 放缓的应对。
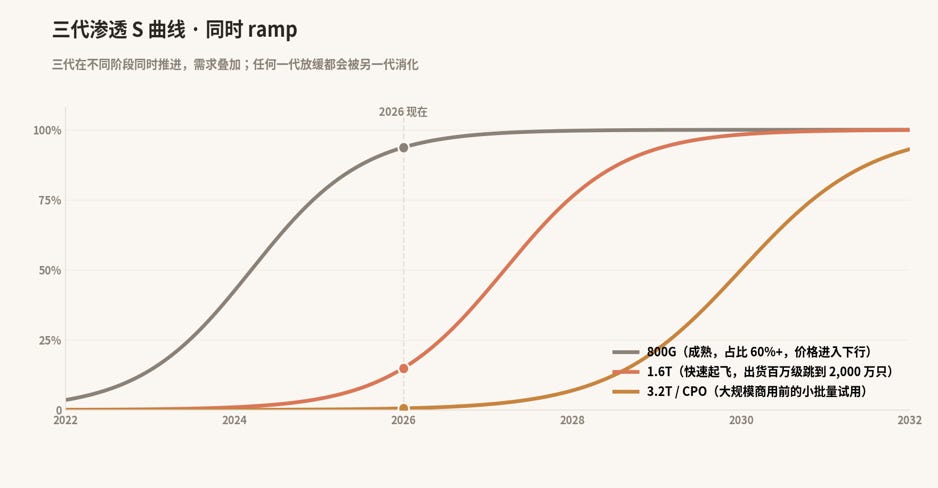
三代渗透节奏: 800G 已经成熟,占比 60%+,价格进入下行通道。1.6T 正在快速起飞,出货从百万级跳到 2,000 万只,单价 $1,000+ 仍维持。CPO / Optical I/O 还在大规模商用前的小批量试用阶段。下面这张图把三代的渗透曲线叠在一起:三代在不同阶段同时 ramp,给组件供应商带来多重需求叠加,任何一代放缓都会被另一代消化。
capex 端的风险点:一,2026 到 2027 hyperscaler capex 有 20% 到 30% pullback 风险,当前股价已 price in 完美执行,任何 miss 触发估值倍数压缩。二,单价侵蚀加速,1.6T 从 $1,200+ 到 2027 的 $700 到 900,模块厂毛利率承压。三,光电集成占 capex 比上升慢,从 2.7% 到 4.1% 用 5 年,意味着光电集成不是 capex 的最大受益方。
3.3 跨代都受益的是路径独立的位置,路径绑定的每代则会有危险,但也有起伏的机会
Lumentum 在 CW 激光器和 InP EML 双线 IDM,CW 业务跨 LPO / CPO / TFLN 都受益,EML 业务面临 TFLN 渗透风险但有 2027 前长协窗口。Broadcom 和 Marvell 在 LPO 时代承压但能靠 ASIC 业务对冲,Marvell 还在 2026 年 2 月以 $3.25B 收购 Celestial AI 进入 Optical I/O。MACOM 的 Driver / TIA 是路径独立组件,LPO 和 CPO 都用,加 NVIDIA 自产链唯一供应商是双重确定性。NVIDIA 在 CPO 之后会成为整个网络层的平台主导者。
最稳的位置:在路径独立这一列:CW 激光器(Lumentum / Coherent)、Driver / TIA(MACOM)、先进封装(TSMC)、精密代工(Fabrinet)。承压的位置在路径绑定这一列:DSP(Broadcom / Marvell 都承压但有 ASIC 对冲)、外购模块(Innolight 最被挤压)。
更纯粹的路径:是设备与量测层。键合设备、装配对准、晶圆级测试这些环节,不管哪条路线赢都要用,是典型的卖铲子。它内部也有价值迁移:InP 外延设备绑定 InP 激光器,被 TFLN / 硅光替代就转移;晶圆级测试随集成度提高只增不减,是这一层确定性最高的。这层在五代上分布不均匀,价值真正放大在 Gen 4 CPO,因为那一代封装才从配角变成决定良率的命门。
InP(磷化铟)是做激光器的衬底材料。激光器要先在 InP 衬底上一层层"长"出半导体结构,这个生长工序就是外延(MOCVD/MBE)。Veeco、AIXTRON 卖的就是干这个的外延设备。所以这套设备的需求量,直接取决于全行业要生产多少颗 InP 激光器——这就是"绑定"的意思。InP 激光器造得越多,外延设备卖得越多。
TFLN(铌酸锂薄膜)替代的是调制器,不是激光器。EML 这个器件是激光器 + 调制器做在一起的。1.6T 往 3.2T 走的时候,InP 做的调制器带宽不太够,TFLN 调制器性能更好,可能把调制这部分从 InP 方案替换掉。但激光器本身大概率还是 InP(TFLN 不发光,只调制)。所以 TFLN 渗透,影响的是 InP 在 EML 里调制器那部分的份额,对纯激光器的 InP 外延需求冲击有限。
硅光替代的是光引擎的集成方式。传统方案激光器单独用 InP 做,硅光方案是想办法把激光器集成到硅基上。但硅本身不发光,到今天为止,主流硅光方案的光源还是得用 III-V 材料(InP/GaAs),要么贴上去(flip-chip),要么键合上去(wafer bonding,OpenLight 那种),要么直接长上去(Aeluma 的 MOCVD on Si)。所以请注意,是InP 用量和形态在变:从一颗颗独立 InP 激光器,变成集成进硅光的 III-V 增益区。
TFLN 在高速调制(3.2T及以上)这一环技术前景更被看好、增速最快,但它替代的是调制器这个零件,不能替代 InP 的单片集成和自带光源能力。产业的实际走向是按场景分代际并存,TFLN 抢调制、InP 守集成、硅光走产能,而且越来越多是混合集成把它们拼在一起,而不是一个平台通吃。所以异质混合集成相关的工艺封装量测会变得越来越重要。

3.4 每家头部公司都有 bear case,市场还没定价
护城河的另一面,是每家头部公司可能出错的具体场景和时间窗口。
• Lumentum:EML 被 TFLN 蚕食的速度。TFLN 在 2027 到 2028 拿到 30%+ 渗透率,EML 业务(占营收约 50%)承压。光库科技、Liobate 已 145GHz 量产。缓解:CW 业务路径独立,TFLN 渗透对 CW 反而利好。
• Coherent:6 英寸 InP 量产延期。原定 2026 底贡献产能,如果延期到 2027 H2,错过 1.6T 周期最高利润窗口。缓解:CPO ELS 三家之一保障份额。
• Broadcom:DSP 在 LPO / CPO 中被消灭,加 ASIC 客户集中。AI 半导体 60%+ 来自单一客户(Google TPU)。缓解:自家 CPO Bailly 方案加 ASIC 客户多元化(OpenAI、Anthropic)。
• Marvell:Celestial AI 整合执行风险。Photonic Fabric 25× CPO 带宽是 marketing 数字,实际可达性未验证,商业化时间表至少到 2028。缓解:DSP 现金牛加 NVLink Fusion 战略绑定。
• MACOM:Driver / TIA 被 ASIC 厂直接集成。3nm / 2nm 工艺让 ASIC SerDes 能直驱光学,独立 chiplet 空间收窄。缓解:CPO 阶段独立 chiplet 仍是主流,加防务业务(占 20%)对冲。
• Ayar Labs:商业化延期,加 dilution,加 Optical I/O 路线非主流。估值 $3.75B 但 pre-revenue。NVIDIA 同时投了多家 Optical I/O 初创,Ayar 未必赢。
• Lightmatter:3D 共封装良率,加量产时间表。M1000 114Tbps 是 demo 数据,规模化良率未验证,2027 H2 是关键验证窗口。
• Innolight:NVIDIA 自产率扩张,加 CPO 长期蚕食。地缘政治风险和实体清单叠加。
贯穿所有玩家的系统性风险:
• AI capex 2026 到 2027 有 20% 到 30% pullback 风险,当前股价已 price in 完美执行,任何 miss 触发估值倍数压缩。
• 光电集成股票已 priced for near-perfect execution。1.6T 单价从 $1,200+ 压缩到 2027 的 $700 到 900,模块厂毛利率承压。
• 地缘政治尾部风险。InP 原料 70% 来自中国,光模块 BoM 重度依赖中国供应链(中际旭创、新易盛、天孚通信等)。美国实体清单加中国出口管制是双向风险。
这一波涨幅里,反方都在,只是还没被定价进去。
3.5 最为核心的是 CW 激光器、Driver/TIA 和先进封装
未来 12 到 18 个月,几个指标决定上面的判断站不站得住:
• NVIDIA 1.6T 自产率(50%+ 兑现速度),决定 Innolight 这类外购模块厂的天花板。
• LPO 在 800G 部署的渗透率(2026 是否真到 1/3+),决定 MACOM 和 Meta 路线的速度。
• NVIDIA Quantum-X CPO 2026 H1 实际出货量(真量产还是只见样品),决定 CPO 兑现还是 LPO 接管 1.6T。
• Coherent 6 英寸 InP 量产时间表(2026 底贡献产能还是延期 2027 H2),决定 Lumentum 长协窗口的稀缺性。
• TFLN 调制器渗透 1.6T 二供地位的速度,决定 Lumentum EML 业务的中期天花板。
• AI capex 2026 到 2027 回撤信号(TOP5 hyperscaler 季度 guidance),决定整条赛道的估值压缩风险。
光电集成链路在换代,赚钱的环节每一代都换位置。CW 激光器、Driver / TIA、先进封装、精密代工这几个零件,从 Gen 1 到 Gen 5 都还在卖,每代都有需求。DSP 在 LPO 时代被消灭,外购模块在 CPO 时代被光引擎替代,路径绑定的位置每代都被压缩。
感觉就是目前的价格已经没有漏网之鱼了🥲